Hadoop是一个开源的、由Apache软件基金会所开发的分布式计算框架。其核心设计灵感来源于Google的MapReduce和Google File System论文。Hadoop旨在通过简单的编程模型,在由大量廉价硬件组成的集群中,对海量数据集进行可靠的、可扩展的分布式处理。它让用户无需深入了解分布式系统的底层细节,就能轻松开发出处理PB级别数据的应用程序。
Hadoop的核心生态系统主要由以下几个关键组件构成:
- Hadoop分布式文件系统:一个高度容错的分布式文件系统,设计用于在低成本硬件上运行。它将大数据文件切割成块,并分散存储在整个集群的多个节点上,默认提供三副本冗余机制来保证数据安全。
- Hadoop MapReduce:一个用于并行处理海量数据集的编程模型和软件框架。其处理过程分为两个阶段:Map(映射)阶段对输入数据进行筛选和排序,Reduce(归约)阶段对Map的结果进行汇总,从而得出最终结果。
- Hadoop YARN:在Hadoop 2.0中引入的资源管理和作业调度平台,它将资源管理与具体的计算框架解耦,使得Hadoop可以运行除MapReduce之外的其他计算模型,大大提升了集群的利用率和灵活性。
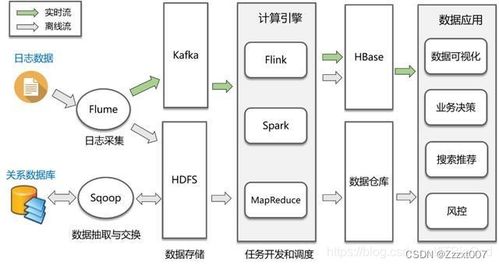
除了核心组件,丰富的子项目构成了强大的Hadoop生态系统,例如用于数据仓库的Hive,用于分布式数据库的HBase,用于数据采集的Flume和Sqoop,以及用于协调分布式服务的ZooKeeper等。
Hadoop的应用场景极其广泛,已成为各行各业处理大数据的首选平台:
- 互联网与社交媒体:用于用户行为分析、广告精准投放、推荐系统(如电商产品推荐、新闻资讯推送)和社交网络关系挖掘。
- 金融行业:应用于欺诈检测、风险建模、信用评估和股票市场趋势分析。
- 电信行业:处理通话详单,进行网络质量监控和用户位置分析。
- 医疗与生命科学:用于基因序列分析、疾病研究和医疗影像存储分析。
- 零售与物流:优化供应链、分析销售趋势、管理库存和规划物流路线。
值得注意的是,虽然Hadoop在在线数据处理领域有广泛应用(例如,通过HBase支持低延迟的随机读写,或通过Spark Streaming进行近实时流处理),但其最初的设计重点在于离线批处理。传统的Hadoop MapReduce模型在处理海量历史数据、进行复杂ETL(提取、转换、加载)和批量分析方面表现卓越,但其高延迟的特性并不适合需要毫秒级响应的在线交易处理业务。
典型的在线交易处理系统,如银行核心交易系统或电商订单系统,要求极高的并发性、强一致性和低延迟,通常由关系型数据库或新型的分布式关系数据库来承担。而Hadoop更多地扮演着“数据仓库”或“数据湖”的角色,存储来自OLTP系统的历史交易数据,并对其进行后续的批量分析、数据挖掘和报表生成,为商业决策提供支持。这种分工协作的模式——OLTP系统处理前端交易,Hadoop生态系统进行后端大数据分析——构成了现代企业典型的数据处理架构。
Hadoop作为大数据技术的先驱和核心,以其高可靠性、高扩展性、高容错性和低成本的优势,成功解决了海量数据的存储和计算难题,为大数据分析铺平了道路,并持续推动着数据驱动决策时代的到来。